
Attention is all you need
In 2017, researchers from Google AI published a research paper titled Attention Is All You Need in which they proposed and described an alternative to both Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN), especially in the context of Natural Language Processing (NLP).
Four years later, the bold assertion at the head of their paper seems to have come true in the field of NLP and is quickly gaining traction in others. Indeed, the so called Transformer Neural Network architecture is revolutionizing the field of Artificial Intelligence (AI) overall, outperforming competing state-of-the-art architecture while requiring fewer resources, surpassing human performance in many tasks and unlocking totally new use cases.
So, what problem(s) did this new architecture solve, how did it solve them and what’s the tangible impact for researchers and the industry?
The pre-Transformer era
Back in 2017 and before, the Artificial Neural Networks landscape was dominated by two classes of networks: Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN). The sequential nature of the former and the shift invariance of the latter made them the solution of predilection for NLP and Image Processing, respectively.
Despite RNNs having had success in the context of NLP, they exhibited two main weaknesses:
- they were not able to handle long sequences satisfyingly mainly because they were not able to keep track of all the relevant information in the sequence
- they were slow to train because their sequential nature made them hard to parallelize
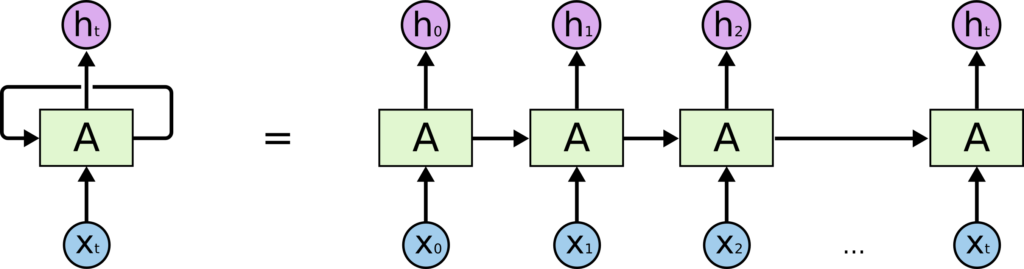
While the first weakness was mitigated by the use of more sophisticated RNN architectures (e.g. LSTM and GRU) and the addition of components like attention, the second issue remained. This inability to scale the performance of RNNs sets a limitation on the size of the networks we can use and the amount of data we can leverage. Two factors which are highly influential in regards to the final performance of the trained networks.
The novel Neural Network architecture
In a broad sense, Transformers are designed to handle sequential data such as natural language, just like RNNs. However, there are two key differences that make Transformers truly shine.
The first difference is that while RNNs have merely adopted attention mechanisms, the Transformer architecture is based solely on it, dispensing with recurrence and convolutions entirely.
The second difference comes from the fact that unlike RNNs, Transformers process their inputs fully in parallel. As such, they can be efficiently trained by leveraging modern GPU capabilities.
From an operational point of view, starting from a sequence of inputs, the model produces an equal length sequence of contextualized outputs, meaning that each output element will be fully aware of all other elements in the sequence, thanks to the attention mechanisms.

The Transformer domination: impact & highlights
The parallel nature of Transformers and the associated significant training performance gains greatly contributed to democratize the use of big models trained on massive amounts of data, which in turn lead to significant performance gains on downstream tasks and even enabled new use cases. This is especially true in NLP, for which we highlight a few interesting cases:
- Google is using the BERT Transformer in its search service to provide better results by having a deeper understanding of user queries. According to them, it represents one of the biggest leaps forward in the history of Search.
- OpenAI’s Transformer model, GPT-3, greatly improves existing NLP use cases and enables new ones without requiring task-specific fine-tuning. GPT-3 has been called one of the most interesting and important AI systems ever produced.

As Transformers were initially created to overcome the shortcomings of RNNs on natural language data, they primarily shine in the context of NLP, where we can safely say that they now replaced older RNN models such as LSTM or GRU. But recently, Transformers have started to show their tremendous potential in other fields, namely Image Processing and Pharmaceutical Chemistry:
- Object Detection: the DETR model matches the performance of the current best models while removing hand-coded prior knowledge and using half the compute budget.
- Image Classification: the ViT model outperforms comparable state-of-the-art CNN with four times fewer computational resources.
- Chemical Synthesis: Molecular Transformer unlocks efficient chemical synthesis planning to accelerate drug discovery workflows, requires no handcrafted rules and is 10% more accurate than the best human chemists.
Will Transformers rule them all?
The Transformer is a relatively new architecture which significantly changed the AI landscape. Their ability to efficiently process sequential data and their great representation power rapidly made them the model of choice for NLP problems. After having dominated the NLP landscape, they are now starting to shine in other fields where they significantly outperform the current state-of-the-art.
It is interesting to note that the apparent supremacy of Transformers is not only due to their great representation power and their powerful attention mechanism but also (maybe even more) due to their highly parallel nature and their ability to scale. This has made the development & operations of complex NLP, Image Processing and Chemical Synthesis system quicker and cheaper.
Transformers then appear to be fully equipped to tackle our most difficult AI challenges across fields and disciplines. In the end, one may wonder: will Transformers soon be the single go-to solution for all AI applications?

Ali Hosseiny
Data Scientist – Uncovering gems with AI
Ali Hosseiny is a Data Scientist at Artifact. Passionate about Artificial Intelligence and Data Science, he’s keen on understanding their ins and outs to wisely leverage their potential for accelerating value realization. He has a broad expertise in AI and Data Science tools and technologies.
Artifact SA
Accelerating Impact with AI & Data Science
Spearheading in AI & Data Science to accelerate impact for your business in Switzerland. Pragmatic analytics services leader for consulting & implementation.
0 Comments